OCR
In this tutorial we will demonstrate how to use StructED for a classical structured prediction task - Letter sequence recognition. For this tutorial we will use the standard benchmark OCR dataset of Rob Kassel, you can download the full data set from OCR.
A Little Bit About The Task
This dataset contains handwritten words collected by Rob Kassel at MIT Spoken Language Systems Group. Each word were pre-segmented into charterers. Each character is represented as a 16x8 binary image. The task is to classify the image into one of the 26 characters a-z. The first letter of every word was omitted as it was capitalized and the task does only consider small caps letters. Our goal is to exploit the correlations between neighboring letters in order to create more accurate predictions of words.
Clearly there are more interesting ways to solve this problem, but we want to demonstrate how to use StructED with more complex inference.
Clearly there are more interesting ways to solve this problem, but we want to demonstrate how to use StructED with more complex inference.
The Code
Here, we present what classes do we need to add and what interfaces do we need to implement. We provide the source code for all of the classes and interfaces.
First, we should setup our development environment. Open a Java project and add the StructED jar file to your build path (it can be found under the bin directory at StructED repository). You can download all StructED source codes and jar files from GitHub.
Note, if you would like to use one of our datasets for any of the tutorials or unit tests, you should copy the data folder to the project directory or change the path in the marked places in the code to the where you store the data.
Now let's begin!
First, we should setup our development environment. Open a Java project and add the StructED jar file to your build path (it can be found under the bin directory at StructED repository). You can download all StructED source codes and jar files from GitHub.
Note, if you would like to use one of our datasets for any of the tutorials or unit tests, you should copy the data folder to the project directory or change the path in the marked places in the code to the where you store the data.
Now let's begin!
Task Loss
In order to add new loss/cost function one needs to implement the ITaskLoss interface. For this tutorial we implemented a 0/1 loss for every letter in a given word sequences:
In other words, the loss is the average character error for the whole word. The loss will be one if y is not equal to $\hat{y}$ in every letter in the word, and zero when they are the same.
The code for the loss function can be found at src.com.structed.models.loss.TaskLossOCR.java on StructED GitHub repository.
\begin{equation} \label{eq:loss} \ell (y,\hat{y}) = \frac{\sum_{i=1}^m{\mathcal{1}\!\left[y_i \ne \hat{y_i}\right]}}{m} \end{equation}
In other words, the loss is the average character error for the whole word. The loss will be one if y is not equal to $\hat{y}$ in every letter in the word, and zero when they are the same.
The code for the loss function can be found at src.com.structed.models.loss.TaskLossOCR.java on StructED GitHub repository.
Inference
The inference for this task involves some dynamic programing in order to get the best sequence of words. The inference procedure we implemented is the same as in: Max-Margin Markov Networks by Ben Tasker et al.
The code for the inference procedure can be found at src.com.structed.models.inference.InferenceOCR.java on StructED GitHub repository.
The code for the inference procedure can be found at src.com.structed.models.inference.InferenceOCR.java on StructED GitHub repository.
Feature Functions
The feature functions we use are the same as in Max-Margin Markov Networks by Ben Tasker et al.
We use the image values with additional indicator feature for the previous letter.
The code for the feature functions can be found at src.com.structed.data.featurefunctions.FeatureFunctionsOCR.java on StructED GitHub repository.
We use the image values with additional indicator feature for the previous letter.
The code for the feature functions can be found at src.com.structed.data.featurefunctions.FeatureFunctionsOCR.java on StructED GitHub repository.
Running The Code
Now we can create a StructEDModel object with the interfaces we have just implemented, all we have left to do is to choose the model. In this example code we were inspired by PyStruct package, and compared between the multi-class approach (classify for each letter without paying attention to the previous one) and the structured approach (with a special feature for the previous letter).
Here is a snippet of such code (the complete code can be found at the package repository under tutorials-code folder):
After running the code the results suppose to be around:
Multi-class: 0.29% error rate
Structured: 0.22% error rate
Here is a snippet of such code (the complete code can be found at the package repository under tutorials-code folder):
// ===================== MULTI CLASS ===================== //
Logger.info("================= Multi-class version =================");
Logger.info("Loading data...");
// === LOADING DATA === //
InstancesContainer ocrAllInstancesMulti = reader.readDataMultiClass(dataPath, Consts.TAB,
Consts.COLON_SPLITTER);
InstancesContainer ocrTrainInstancesMulti = getFold(ocrAllInstancesMulti, 1, true);
InstancesContainer ocrTestInstancesMulti = getFold(ocrAllInstancesMulti, 1, false);
if (ocrTrainInstancesMulti.getSize() == 0) return;
// ==================== //
W = new Vector() {{put(0, 0.0);}}; // init the first weight vector
arguments = new ArrayList() {{add(500.0);}}; // model parameters
// ======= PA MULTI-CLASS MODEL ====== //
// create the model
StructEDModel ocr_model_multi_class = new StructEDModel(W, new PassiveAggressive(),
new TaskLossMultiClass(), new InferenceMultiClass(Char2Idx.char2id.size()-1), null,
new FeatureFunctionsSparse(Char2Idx.char2id.size()-1, maxFeatures), arguments);
ocr_model_multi_class.train(ocrTrainInstancesMulti, null, null, epochNum, isAvg, true); // train
ocr_model_multi_class.predict(ocrTestInstancesMulti, null, 1, false); // predict
// ======================================================= //
// ====================== STRUCTURED ===================== //
Logger.info("================= Structured version =================");
// === LOADING DATA === //
InstancesContainer ocrAllInstances = reader.readData(dataPath, Consts.TAB,
Consts.COLON_SPLITTER);
InstancesContainer ocrTrainInstancesStruct = getFold(ocrAllInstances, 1, true);
InstancesContainer ocrTestInstancesStruct = getFold(ocrAllInstances, 1, false);
if (ocrTrainInstancesStruct.getSize() == 0) return;
// ==================== //
// ======= PA STRUCTURED MODEL ====== //
W = new Vector() {{put(0, 0.0);}}; // init the first weight vector
arguments = new ArrayList() {{add(15.0);}}; // model parameters
StructEDModel ocr_model = new StructEDModel(W, new PassiveAggressive(),
new TaskLossOCR(), new InferenceOCR(), null,
new FeatureFunctionsOCR(maxFeatures), arguments); // create the model
ocr_model.train(ocrTrainInstancesStruct, null, null, epochNum, isAvg, true); // train
ocr_model.predict(ocrTestInstancesStruct, null, 1, false); // predict
Graph g = new Graph();
g.drawHeatMap(ocr_model, start_transition_characters, nam_of_characters);
// ======================================================= //
After running the code the results suppose to be around:
Multi-class: 0.29% error rate
Structured: 0.22% error rate
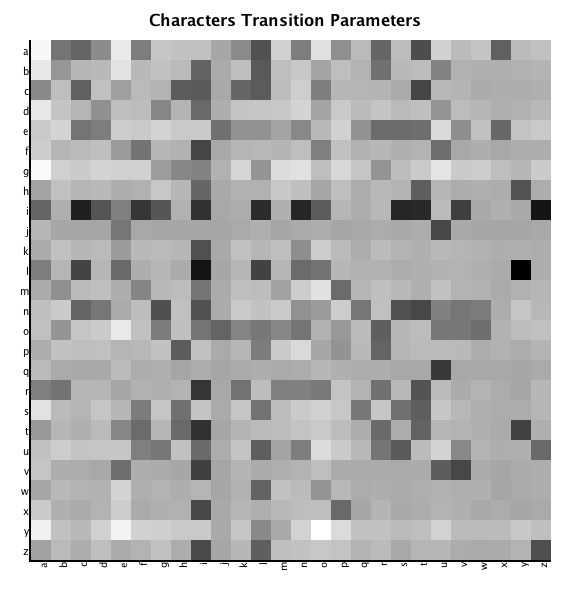
In addition we generated a plot of the previous letter feature. We can consider this feature as a character transition matrix, the probability for two letter to appear one after the other.